Content Addressing & Verifiability in Fleek Network

We’ve been expanding on how a decentralized edge architecture can optimize how web3 services and protocols are delivered. Another core aspect of the edge architecture we’ve designed that help us achieve that is:
Performant and verified content addressing & streaming of all data, from files cached by the CDN service to a JS function to be computed by a service that passes through Fleek Network and its services. How is that achieved? By using Blake3, a content hashing algorithm.
The TLDR is that Fleek Network:
- Is content addressable at its core, addressing all data by content hashes.
- Uses Blake3 to hash stream and verify data in chunks, with parallel processing.
- Provides proofs of file size and streaming of specific segments of a piece of data.
- Uses a streaming library based in BAO, with optimized chunking/verification.
- Enables full verification without sacrificing performance/latency.
What does it mean that Fleek Network has a content addressable core?
As we shared in our previous blog, edge networks at their core apply the concept of geo-distributed work allocation, to not just the caching/serving of data (CDN), but to an additional suite of web and edge services (compute, SSR, databases, container orchestration, etc.). Think of it as a CDN sitting on top of not just data being cached and served, but on the requests for all services (ex. a client requests a serverless function to execute) and the corresponding responses (ex. a node replies with computed result).
This means a lot of data is streamed in edge networks for MANY purposes, between nodes and clients. And the same applies to Fleek Network.
To achieve that in a performant way, in a nutshell, the network bakes the core primitive of IPFS (IPLD) and content addressability (using Blake3) into the network. All data in Fleek Network is linked and addressed via a hash that represents its content. If the content changes, it will be represented by a new/different hash. More so, files can be divided into pieces/chunks for efficient streaming, and each chunk receives a hash which represents that chunk as part of the file as a whole.
These sub-hashes are not stored and ephemeral, and given Blake3’s efficiency, it allows clients to compute them on the fly and verify that they belong in the file as a whole. How fast? We can stream data and verify it trustlessly with virtually no latency ( ≈45 nanoseconds).
What’s the relationship between Blake3 and IPFS/IPLD?
Blake3 is an IPFS compatible content hashing algorithm. Both IPFS and IPLD support the usage of Blake3 hashes (among other hashing algorithms). We decided to use Blake3 for Fleek Network because of its overall performance and features that align perfectly with the edge network use-case.
If Fleek Network fetches any data from IPFS that has been hashed with a different algorithm, it will simply receive those other hash types and map them to their Blake3 equivalent hashes to maintain Fleek Network’s standard and efficiency while still maximizing compatibility and flexibility regarding hashing.
What are the overall benefits of using this approach?
The main benefit is being able to achieve full verification without impacting performance/latency. For example, the network streams data piece-by-piece. Blake3 allows us to verify this data along the way, chunk by chunk - allowing us to still deliver files in a performant way, without its verification hindering performance. This means:
- If the file fails mid-way, the verification will catch it earlier than later.
- If everything is ok, the end-client gets data procedurally, and faster.
- Given files are chunked, multiple nodes can parallelize and help stream the data faster.
That’s not just great for use-cases like video streaming, but to also propagate data across nodes on Fleek Network extremely fast if, for example, they need to quickly scale up a compute function to a lot of new nodes.
Also, since file hashes are very small in size (i.e a 1600 Petabyte file would still always produce a 32 bytes hash) optimize the entire network’s system of inter-node communication and interaction: when nodes gossip/communicate, they speak of hashes, not “full files”. Overall, it’s a great performance optimization across the network and several functionalities.
What's Blake3 Role in this?
Blake3 in short is a hashing algorithm. It does not handle the processing of data or fetching keys, it simply takes the data and provides the appropriate hash. The network uses this hash to address and retrieve data, and because Blake3 uses merkle tree structure to generate this hash, it can verify the content/data as it is received incrementally (chunk by chunk). Blake3 starts at the bottom of the tree, and builds its way up to the root hash determining the data is complete.
In a distributed/decentralized system, trustlessness is key, and Blake3 enables trustless data streaming at a performance level ideal for a decentralized edge network and on par with centralized alternatives.
The root hash represents the whole file, and then Blake3 works its way up the tree in pairs to verify the data chunk by chunk. MO and M1, as hashes, also represent the pair of hashes below (and so on).
How is verified streaming optimized?
We have built a custom data streaming/verification library, based on BAO, that allows the sending of an early pruned tree, and procedurally handles the rest when needed. The receiver only needs enough to verify its way up from the bottom to the root hash, not the entire horizontal tree. So, we can bring our scissors and do a little merkle-tree pruning ✂️:
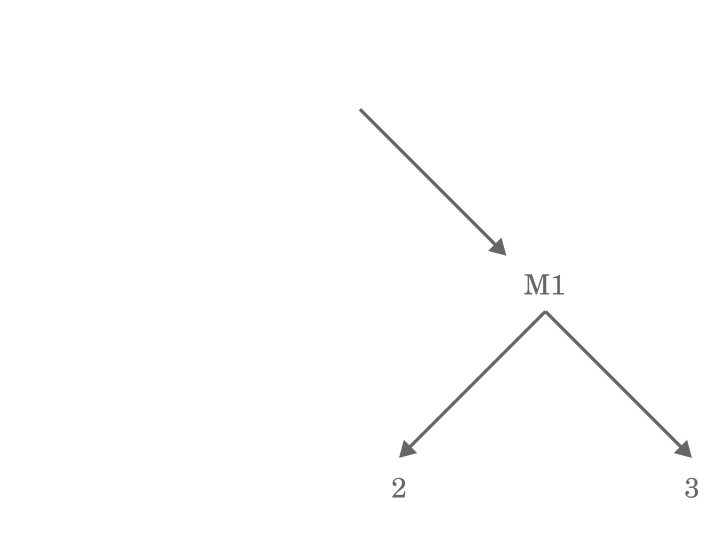
This custom library also allows another performance optimization, where we can send a smaller hash initially (left side), and then procedurally send other necessary hashes as the respective data chunks are sent along and need verification.

Plus, having an initial estimate of the entire tree structure, and knowing data is chunked in 256kb pieces, the network can conduct efficient proof of size, easily predicting and proving the file’s size before it has arrived. The chunk file-size is also a redefinition from BAO’s implementation, originally set at 1kb, generating smaller hash-trees and data-chunks that are faster to generate but still easy to stream.
Blake3 not only allows file size prediction, but with the parallelization mentioned above, nodes can process this at a multi-cpu-core-level and actually stream independent chunks/hashes of the tree from different nodes, building the tree up many layers at a time. That’s performance optimization working overtime for you. :)
Is all data mapped to a Blake3 hash?
Yes! Fleek Network uses Blake3 to address all data coming and going in the network, regardless of their source/origin.
The interesting aspect is that Fleek Network uses a Distributed Hash Table (DHT) to keep a permanent mapping of any given data’s hash to all of its historic origins. Much like a CDN, we map where the file came from (origins, single or multiple), and its associated hash in the network, so that if the file’s needed again it can be re-fetched and re-cached by the network’s nodes. Fleek Network’s also capable of mapping mutable data, e.g. from https origins, to Blake3 hash!
This adds a couple of cool features to the network:
- We can unify files from any source under a single type of ID: Blake3 hashes.
- One hash/file can have multiple origins, for redundancy, under the same hash.
- Given the above, if an origin fails, we can easily fall-back to another to re-fetch.
Once again, performance is core to the concept of an edge, and especially in a decentralized edge network the optimized verification of data is key - which makes Blake3 an excellent choice for the network’s needs. Stay tuned as we run onwards towards the updated whitepaper release this month, where we’ll be sharing more on this - and other performance characteristics of the network. ⚡ Until next time!