Living On The Edge: A Dive Into Edge Networks

Last week we dropped some alpha on Fleek Network’s updated plans/roadmap for a decentralized edge network, including a new whitepaper being released this month (July). In preparation, we figured it would be helpful to go more in-depth on what an Edge Network actually is, and why they are becoming increasingly important for the web.
Here is the TLDR version:
- An edge server architecture takes computing, data & delivery closer to end users, instead of using centralized servers
- It combines the best parts from CDNs and serverless architecture to do it fast & scalable
- We need edge because latency & performance are a huge deal for end users
- This is a standard for the modern web, so bringing it to web3 can make a big impact
Now for the more in depth version :)
What is the Edge?
In short, what we call “the edge” is a distributed network of servers that allow developers to store, compute and serve content as close to users as possible, using location and a smart topology of the network to reduce latency and improve performance. Having your app, files, computation, or services on “the edge” means hosting/executing them on multiple servers worldwide, so these can be served close to the user/client that needs it, rather than having to funnel it back –and far– to a centralized, unique server.
Edge gets its name from early web architecture. As data started to be created everywhere, with continuous needs for processing and computing, the “cloud” reached the ceiling of what can be optimized inside a central center to meet this demand. Instead, to maintain performance, and scale these new use-cases popping up (e.g. streaming), the web moved to the literal “edge” of the network, right besides the data, clients, and users, and started executing there instead of bringing everything back home to the main servers.
This idea of geographic proximity originated from Content Delivery Networks (CDNs), a widely adopted concept on the modern web. But besides caching and delivering data performantly, like CDNs, edge networks can optimize tasks that are heavy duty for end users, such as fast storage/retrieval, streaming and continuous/live compute. Some examples include server-side rendering for modern frontend frameworks (e.g. Next.js) , CRDT-based databases, and image/data optimization (SSR), all services that benefit and scale better running in multiple locations at once, rather than a central server.
Why do we need edge networks?
Latency
Latency, the time it takes for data to pass from one point on a network to another, has to be as low as possible to provide a good user experience on the modern web. High load times are the bane of web developers: according to Google, the chance of a bounce –a user abandoning the site– increased by 32% when a page load time went from one to three seconds, and by 90% when the page load time went from one to five seconds.
From the user’s perspective, speed is essential. We’ve learned to expect sites and applications to load instantly, and when our browsers take more than a couple of seconds than normal, our “something’s wrong” instinct kicks in instantly. But the real challenge is data that needs to be processed and delivered in near real-time with low tolerance for latency, like gaming on-demand via streaming.
As you may have deduced already, most latency issues are caused by distance: servers and end users are sometimes far away from each other, and those extra milliseconds add up. A practical example: two pings from the same region in Santiago, Chile. First, to a local server…
test1$ ping www.nic.cl -c 3
PING www.nic.cl (200.7.7.3): 56 data bytes
64 bytes from 200.7.7.3: icmp_seq=0 ttl=57 time=10.623 ms
64 bytes from 200.7.7.3: icmp_seq=1 ttl=57 time=8.988 ms
64 bytes from 200.7.7.3: icmp_seq=2 ttl=57 time=20.704 ms
- -- www.nic.cl ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 8.988/13.438/20.704/5.181 ms…and the second to the other side of the world, in Russia:
test1$ ping www.nic.ru -c 3
PING www.nic.ru (31.177.76.4): 56 data bytes
64 bytes from 31.177.76.4: icmp_seq=0 ttl=50 time=275.234 ms
64 bytes from 31.177.76.4: icmp_seq=1 ttl=50 time=315.850 ms
64 bytes from 31.177.76.4: icmp_seq=2 ttl=50 time=285.775 ms
- -- www.nic.ru ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 275.234/292.286/315.850/17.209 msThat is a huge round-trip time, huh? If we were to request a site from Siberia, it would take a considerable amount of time to load compared with a local server. But here’s the real kicker: any web application with low tolerance for latency would be absolutely unusable.
Therefore, closing the gap between client and server is absolutely critical to ensure quality of service for applications. This is where the edge comes in, by distributing edge servers in geographically relevant locations and automatically routing end users to them.
Performance
The modern web is heavy to load and compute, and heavy duty applications are the culprit: real-time streaming & VR/AR not only require bandwidth and low latency, but massive amounts of computing power. Even the most simple websites and apps today are dynamic, taxing our machines with interlocked databases, languages and frameworks.
Sure, when the web started, performance was an afterthought. Static sites –like the Geocities sites we used to visit in ‘99– didn’t need much rendering, but modern frameworks push the envelope to the extreme. Now, data/compute demands are a growing constant, and as we hinted above, some types of compute, processing, and data handling benefit extremely from parallel execution, where edge can shine.
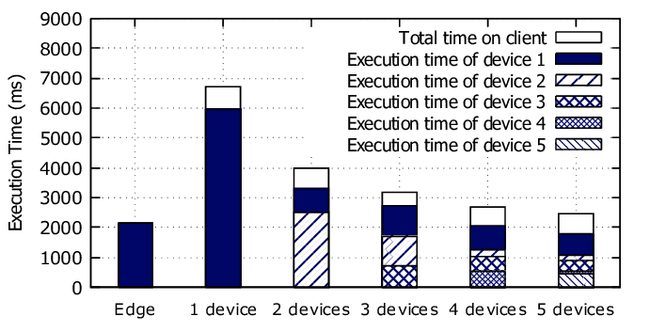
Image processing (as seen below) is a perfect example. Distributing the load in a p2p edge network significantly reduces the execution time needed, getting files back to each user on time, without making their execution dependent on each other, or a single server.
In short, having a distributed edge network means our apps and websites are less resource-intensive for end users, which means less use of CPU and memory on their machines and less chance of browser/app hangs. Also, taking computation away from users means smaller payloads are sent, so less bandwidth is used.
Serverless
Another headache for developers has always been the configuration and capacity planning of servers and data centers. Having a classic cloud model that requires a dedicated DevOps engineer makes no sense if you’re trying to push a simple, low-demand application; this means a lot of computational power goes unused.
The serverless execution model was created to deal with this, simplifying the process of deploying code into production. Solutions like Google App Engine and AWS Lambda started a trend: instead of spinning up servers/resources for each new service or code you need executed, you run it serverless. Simply specify what needs to be done, and how, and the network will allocate as many resources as needed to do so, on-demand.
Normally, the main issue would be distribution. “Serverless” may seem abstracted but it’s still computation performed by centralized servers, far away from end users. But, combined with an edge infrastructure, that situation changes and you have both the benefits of serverless execution, and a geographically aware network. Win/win.
Web3 and the Edge
Web2 and web3 are following a common suit. Micro services on web2 keep our web service simple, and easy to deploy on aware edge networks; and on Web3 we’re seeing the rise of modular and use-specific protocols to cater for each need of the web3 stack.
But, unlike in the modern web, web3 does not have the same performance and orchestration layer that micro services in web2 have on top, abstracting both how these services are executed and delivered to clients. Edge networks, and all the benefits we described above, are the backbone of that layer.
This puts web3 services, protocols, and middleware in a tight spot. Do they compromise and fill this gap using web2 edge - hence making their service more “web2.5” than web3? Or do they start worrying about things outside of your service’s scope and attempt to build this performance/orchestration layer akin to edge, integrated into their own protocol?
Introducing a web3 edge network can help cover some of this issues, so:
-
Bring centralized web-like performance to web3 without sacrificing on web3 values.
-
Lower the barrier of entry and speed up time to market for developers building web3 infra/middleware by offloading a portion of their stack to the decentralized edge.
The key takeaway is this: web3 edge networks could allow the ecosystem to create and enable services, such as CDNs or serverless functions, that are as performant as their web2 counterparts. By providing this common layer, we can imitate the current web2 abstracted dev-experience, and level the field by making it easier for developers of web3 protocols, middleware, services and apps to build their core features, and leave the performance/latency optimizations to the edge layer above, similar to the modern web.
Getting a truly comprehensive view of the edge gets us right on track for the new Fleek Network whitepaper, which will outline the design for a highly performant decentralized edge network.
We’re super excited to share the complete whitepaper with you in the near future. Until then, and if you want to get the details –or haven’t heard of it– you can revisit our most recent update. ⚡ Until next time!