How Content Addressability Gives Fleek Network an Edge

Last week we covered how content addressing and streaming is implemented in Fleek Network using Blake3, and how our custom implementation improves data streaming performance and verifiability.
In addition to the performance benefits, there are other unique advantages content addressability gives to Fleek Network in comparison to traditional edge platforms.
The TLDR is that thanks to content addressability, Fleek Network is able to:
- Serve data faster by using the built-in data chunking and then parallelizing the serving of those data chunks across multiple nodes (instead of serving one big file from one location). Netflix did a great job demonstrating this a few years ago.
- Avoid duplication of data since everything is referenced by a content-addressed hash and not unique names/urls. If a hash is already cached, it’s not re-uploaded or re-cached.
- Provide better data availability guarantees, since a cached data’s hash can be mapped to multiple origins, and can be re-fetched from multiple sources if it falls off cache.
- Perform easy content authenticity and data integrity checks. Since all data is content-addressed, it’s as easy as verifying the content hash did not change to verify it remains unmodified (similar to why NFT’s all use IPFS/content addressing)
Let’s unfold this a little bit further :)
How does content addressing enable faster serving of data?
IPFS/IPLD provide data chunking and hashing functionalities. On one hand, you can chunk files/data and be able to address each specific chunk; and on the other, you can stream and verify that data, one chunk at a time, regardless of order, origin, or means of transport. You can also recompose the data as a whole, and verify that each chunk belongs to it.
With that functionality at hand, you can parallelize the streaming of data chunks using multiple nodes at a time, instead of relying on a single connection between server and client.
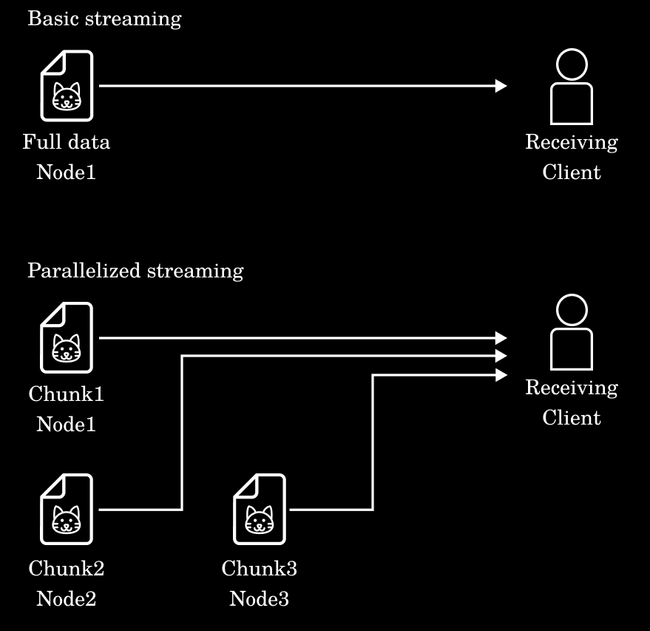
Netflix explored this technology together with IPFS to tackle the challenge of pulling container image files at scale in a multi-region environment, using IPFS as a peer-to-peer CDN.
Netflix was able to achieve performance gains in their developer pipeline over the standard Docker setup of pulling every image file in full from one location (docker hub). They did this by using IPFS as a private p2p node network and CDN that chunked their docker image files and served the chunks in parallel from multiple IPFS nodes.
How does content addressing avoid data duplication?
Automatic data deduplication is a built-in feature of IPLD and IPFS that is possible because of their content-addressed approach. The core concept is simple: Data is addressed by a content hash, which represents the file’s content, and not an arbitrary name/url (e.g. picture.png…). So if the data of the file is the same then the hash will always be the same and unique to that file, so there is only ever a need to store the content relating to a hash once.
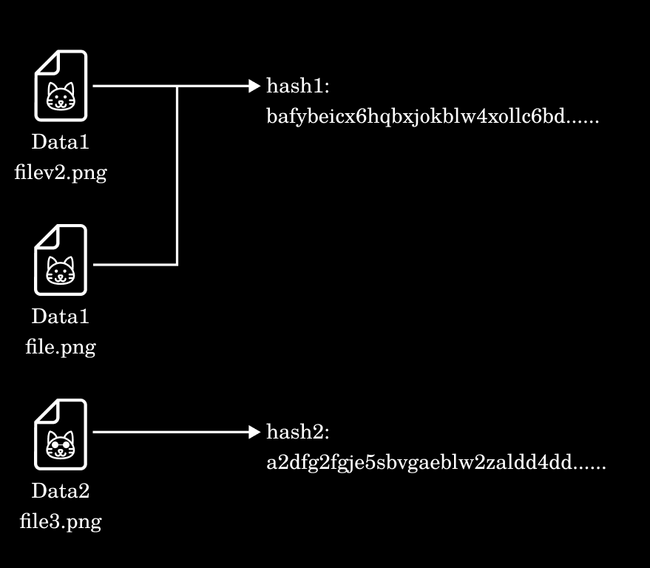
In a nutshell, if you have “file.png” cached on a node already, and a new “image.png” file arrives, but they are the same file… it won’t be saved and duplicated, because they share the same hash and the network knows it is already available.
This is useful for reasons such as
- not needing to re-upload anything that already exists; and
- not paying for redundant storage/caching of the same content
For example, on social media platforms a lot of times the same content (ex. a viral video) is uploaded by tons of different users. But if they were to leverage content addressed data, they could reduce redundant cache/storage/uploads and more efficiently route content.
How can content addressing provide better data availability guarantees?
Let’s review what happens when content falls off a CDN/edge (a normal part of how they work).
CDNs, in short, take files and cache/store them in multiple geographic locations so they can be served fast (closer to the end user requesting them). That storage/caching though is temporary. If users stop needing that file, the CDN will un-cache it after some time until a new request is made. When that new request is made, the CDN fetches the file from the origin (storage layer) and puts it back on the cache layer.
But what if a file’s origin stops existing or the url stops working? In that case the file that is cached by the CDN will become inaccessible once the cache time expires. This is not a minor problem, around 66% of links produced in the last 9 years are dead/lost, and plague the web with errors and lost data. We also have already seen this issue happen with NFT’s that don’t properly handle their metadata (ex. hardcoding a URL rather than the IPFS hash).
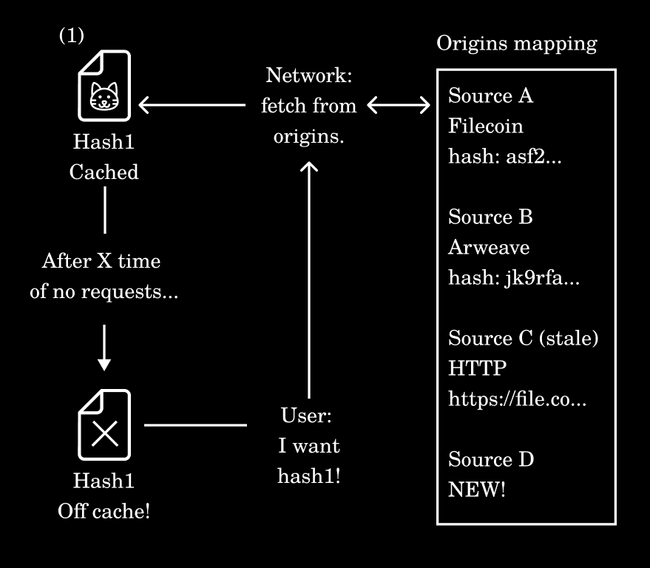
Fleek Network’s edge platform (including the CDN) work under the same principles as traditional CDN’s, but using DHT and content addressing we can easily enable a multi-origin setup for better data availability guarantees:
- Fleek Network uses a decentralized hash table (DHT) to map a file’s hash to its origin.
- It can store multiple origins for any given hash, since it can detect via the content hash if the same file was uploaded from different origins.
- This means that if Origin A falls off, but Origin B is still ok… Fleek Network will still be able to cache and serve the file again.
This mechanism not only allows for seamless redundancy at the storage layer, but it also reduces vendor lock-in and switching costs between storage options, since your files/data are always content addressed it wouldn’t require changes at the app/product level.
How do content hashes simplify content authenticity and data integrity checks?
Last but not least, a tremendous challenge of building a decentralized and trustless edge network is ensuring the data being moved around is always verifiably correct and untampered .
Going back to the basics of content addressing: content is addressed by hashes that represent the content itself. So when sending or receiving any given data - Fleek Network is able to verify the data requested and served is indeed the same by comparing the content hash and having the client verify it’s the same. If the data was corrupted or tampered, the hash would not match.
When you add chunking into the equation, the importance of data verifiability grows exponentially. We dove into how that process is handled in this blog we previously mentioned where we discuss this implementation.
Content addressability has proven to be of great value in Web3 protocols, services, apps, and use cases , and we’re excited to see how we can continue to leverage it in Fleek Network’s architecture and the services built on Fleek Network to improve performance, orchestration of data, or power new use cases Stay tuned as we continue exploring, building and sharing more ⚡.