Testnet Phase {1} Recap: Performance Metrics

Last Thursday marked the conclusion of Fleek Network’s Testnet Phase {1}. As outlined in previous blog posts, Phase {1} was a one-week test period focused on showcasing the potential performance of the edge network for the first time.
Phase {1} turned out to be an enormous success. Seeing 5,000+ nodes successfully running across the network and demonstrating that Fleek Network is capable of being just as performant as web2 cdn/edge platforms and, with further optimizations, potentially even more performant.
Fleek Network has now established an incredibly strong foundation to build upon and is equipped with valuable real-world test data that will accelerate the protocol and performance optimizations even further.
IMPORTANT:
Before jumping into the data, it’s important to note that the Fleek Foundation and core team did their best to follow the same methodologies that other organizations use for performance benchmarking and data/metric calculations to present the results as accurately and fairly as possible. It’s also important to note that TTFB is not the end-all/be-all for measuring cdn & edge performance. In future performance tests, many additional metrics and scenarios will be tracked, and all the performance testing and data collection methodology will be publicized. This was just an initial alpha test to give everyone (including the Foundation and core team) a first glimpse into the real-world performance of the edge network, and so the results should be treated as such.
Now, let’s dive into the data.
Phase 1: Performance Metrics
TLDR:
- Achieved ~70ms TTFB globally (50th percentile), and hit ~25ms TTFB (50th percentile) or lower in multiple key geographies when geo-routing requests
- Proved the additional steps required for Handshake in a decentralized setting adds minimal latency overhead (less than 1ms on average)
- Successfully showcased algorithmic clustering of nodes based on latency
- Demonstrated the network running successfully with 5,000+ nodes
- Used zero web2 infra or augmentation (meaning the results show actual Fleek Network performance, nothing else)
- Accomplished all of this in suboptimal testing conditions (testnet was a free-for-all, node specs were not enforced, no slashing or incentives, several key aspects of the protocol relevant to performance are still early WIPs, etc.)
Time to First Byte (TTFB)
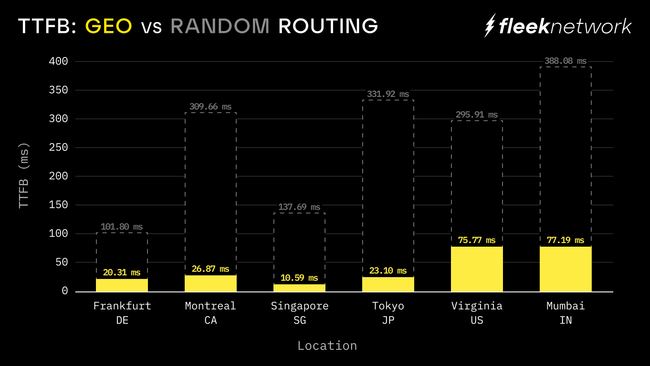 Chart showing TTFB (ms) in different geographies at the 50th percentile mark. Showing both simulated GEO routing as well as random selection.
Chart showing TTFB (ms) in different geographies at the 50th percentile mark. Showing both simulated GEO routing as well as random selection.
As you can see in the chart above, two different scenarios are shown: Random and GEO Routing. The reason for this is that the routing algorithm didn’t apply to Phase {1} is due to several factors (no slashing or enforcement on node specs, fresh reputation on all nodes, etc.), so this was done to simulate things for purposes of this Phase {1}. Basically, for the performance test, all requests were sent to completely random nodes. After the testnet phase, we were able to filter the data to show what it would be if things were simply geo-routed (in a mainnet scenario, the routing would be reputation-based, which takes into account both geography and performance). This was accomplished by filtering requests from each location to nodes within that country.
It’s not a perfect analysis, but it at least gives a general idea. And while it might make the data look better in certain scenarios, it also makes it look worse in others. For example, Virginia is showing TTFB based on requests going to all nodes in the US (filter by country), whereas in a more realistic setting, requests from Virginia would probably be heavily concentrated to nodes close to Virginia, which would make the data better. This will be proven in future performance tests.
Handshake
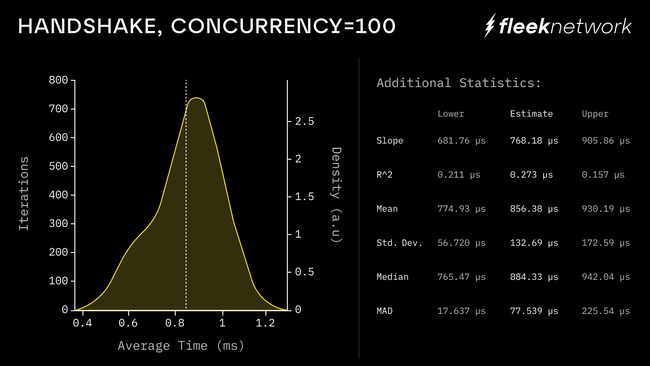 Chart showing that the entire handshake, including the additional steps required due to the decentralized nature of Fleek Network, on average adds less than 1ms of latency.
Chart showing that the entire handshake, including the additional steps required due to the decentralized nature of Fleek Network, on average adds less than 1ms of latency.
To explain the chart above: one of, if not the most important things that needed to be proven in Phase {1} was that the additional steps required for a Handshake in a decentralized setting doesn’t add overhead and negatively impact performance. Web2 cdn/edge networks control all the servers, so they don’t need to do these extra steps, but Fleek Network does. In Phase {1}, we proved that it can be done in a way that doesn’t add any material overhead (less than 1ms on average).
Below are more details about how Fleek Network’s Handshake process works:
During the handshake step of a request in Fleek Network, both the client and the server (node) prove their identity to the other side by exchanging proof of possession of their cryptographic key material. Additionally, given that Fleek Network has a multi-service architecture, at this step, the client will notify the node about the service that it is interested in connecting to, and anything from that point forward is proxied directly through to the core of that service.
An exciting concept in Fleek Network’s design is that the service is oblivious to the actual transport layer the client uses. We can forever add ways for clients to connect to a node without breaking the services. We currently support a custom TCP-based transport, WebTransport, and WebRtc as ways for a client to connect to a node.
Algorithmic Clustering
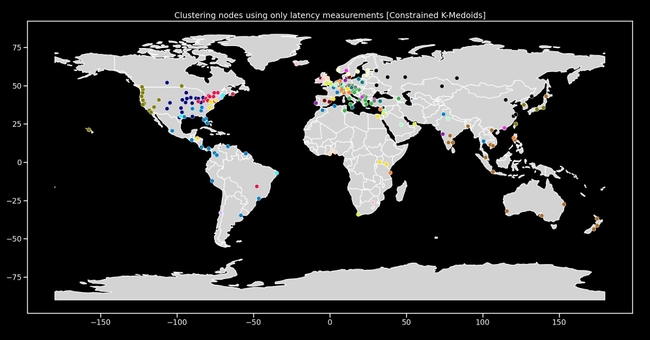 Map showing the algorithmic clustering of nodes, optimizing for latency between nodes and sharing content locally. The different colors represent different node clusters within the network.
Map showing the algorithmic clustering of nodes, optimizing for latency between nodes and sharing content locally. The different colors represent different node clusters within the network.
The map above is also interesting to share. It shows how Fleek Network organizes the network into clusters, optimizing for latency between nodes and sharing content locally. There is a very specific set of requirements for the clustering that dictates the novel solution: the algorithm should be deterministic, clusters should be all around the same size, the algorithm should be resilient to noisy data in the event of bad actors or missing values, and connection pairings should be redundant enough to ensure network churn does not leave any nodes orphaned from broadcasted messages. Keep in mind the network does not have an inherent understanding of geography, but rather collects latency information over time, and uses that to find the ideal clustering for a given epoch.
The map shows how geography somewhat influences latency, but the clusters do not always end up being what you’d think they would be intuitively. This is because the internet has variations in the routes taken between major cities and high-traffic areas, with some being optimized more than others. Additionally, we were able to see the resilience of the algorithm demonstrated due to the state of the network in the beginning of the testnet. For example, there were some issues with nodes not reporting latencies, as some nodes failed to move past the early epochs on their own.
Despite this, the algorithm still managed to form coherent clusters and produce an optimal network layout. In the future, to further support the algorithm, there will also be a ping job running in the node. This will connect to nodes randomly to gather more latencies. This might also be used during an onboarding period, so new nodes will join directly into an optimized place in the network.
Post Phase 1: What’s Next on the Road to Mainnet?
An updated roadmap with new milestones will be released later this month. But the TLDR is as follows:
With this initial performance data in hand and all the learnings from Phase 1, there are a ton of known fixes and improvements to advance the protocol significantly and further optimize performance. The plan is to spend the next few weeks on that, while at the same time doing kit/auxiliary work on things like the SDK, CDK (client development kit), metrics infra, gateways (ex. WebTransport for js-cdk), Rust CDK, etc. The plan is to then set up a controlled test version of the network that will eventually lead to a public long-running testnet (meaning it won’t be taken down).
The first POC service that is planned to launch on the controlled testnet will be serverless compute (ex. Lambda functions). This will enable developers to begin participating in testnet activities in addition to just node operators and provide an ideal opportunity to do a second round of performance testing on a wider range of metrics and use cases.
That’s a wrap on Fleek Network Testnet Phase {1}. This initial performance showcase was the most significant milestone yet, and the data and learnings gathered will be invaluable to the continued development of the project.
The Foundation wants to thank all node operators and community members who participated and helped make Phase {1} a huge success. Stay tuned as more information is released in the coming weeks on the updated road to mainnet and upcoming milestones – follow us on X and join the Discord server to make sure you don’t miss anything.
Fleek Foundation ⚡